Dasar Pengenalan Citra
- citra berisi matriks yang tiap elemennya adalah pixel yang merepresentasikan warna, bentuk, tekstur
- konversi citra RGB (0-255 tiap channelnya) ke grayscale
- pake rata-rata -> $x = \dfrac{r + g + b}{3}$
- pake weighted avg -> $x = a_{r}r + a_{g}g + a_{b}b$ dimana $a_{k}$ adalah konstanta yang mengskalakan tiap channelnya dan $a_{r}+ a_{g}+a_{b} = 1$
- di
pythontinggalcv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
- konversi grayscale (0-255) ke biner (thresholding)
- pakai threshold $\theta$, misal $\theta=128$, maka $\begin{cases}1 \text{ jika } x \geq \theta \ 0 \text{ jika } x < \theta \end{cases}$
- Atau pake rata-rata $\bar{x}$, $\begin{cases}1 \text{ jika } x \geq \bar{x}\ 0 \text{ jika } x < \bar{x} \end{cases}$
- 1 itu artinya nyala/putih, 0 kebalikannya
cv2.threshold()
- Data citra digital disimpan dalam bentuk bit mulai dari 1,4,8,16,24 bits. $1 bit = 2^{1} \text{ macam warna} = \text{biner}$. 8 bit -> gray scale (0-255). 24 bit -> R 8 bit, G 8 bit, B 8 bit.
- Kecemerlangan/brightness -> $f’(x, y) = f(x, y) + C$ dimana makin besar $C$ maka semakin terang. Intuisi -> makin “besar” nilai pixelnya maka makin dekat dengan 255 atau warna putih (“terang”). Untuk citra RGB tinggal di tambah dengan $C$ untuk tiap channelnya.
- Negasi -> $f’(x, y) = 255 - f(x, y)$. Intuisi -> kalo piksel nya 0 jadi 255 dan sebaliknya. Intinya dibalik gitu (hence the name).
- Menggabungkan gambar dengan penjumlahan -> $A \times w_{1}+ B \times w_{2}= C$ dimana $A$ dan $B$ merupakan gambar yang akan digabung dan $w$ adalah bobot yang menentukan intensitas gambar. $\sum\limits_{i}^{n} w_{i} = 1$.
- Transpose -> jadinya menukar baris menjadi kolom dan kebalikannya. Di PPT yang dijelasin bukan transpose, tapi di rotasi biasa.
- Pencerminan -> ditukar kolom pertama jadi kolom terakhir dll. Barisnya tetep sama (ini pencerminan berdasarkan sumbu y / horizontal). Pencerminan vertikal -> barisnya yang ditukar
- Cropping -> motong/slicing koordinatnya
Operasi Geometri
- Translasi -> geser gambar -> $B(x, y) = A(x+m, y+n)$. Piksel kosongnya bakal jadi warna hitam soalnya 0.
- Rotasi -> $A(x, y) = B(x \cos \theta - y \sin \theta, x \sin \theta + y \cos \theta)$, Dimana $\theta$ adalah sudut rotasi.
- Dilatasi/Zoom -> $B(x’,y’)=B(s_{x} \times x, s_{y} \times y)$. Dimana $s_x$ dan $s_y$ adalah faktor penyekalan. Jika $s_{x}= s_{y}$ maka zoom in/out nya akan menjaga aspect ratio. Tapi kalo $s_{x} \neq s_{y}$ maka zoom in/out nya stretched.
INTER_NEAREST-> nearest neighbor interpolation (jele)INTER_LINEAR-> bilinear (default). Perhitungan liat pptINTER_CUBIC-> bicubic
- Pencerminan -> horizontal sumbu y $B(x, y) = A(N-x, y)$, vertikal sumbu x $B(x, y) = A(x, M-y)$. Yang jadi sumbu itu gak diapa apa in.
- Cropping -> $w’ = xR – xL$ dan $h’ = yB –yT$
- Region Of Interest -> bounding box. 2 koordinat yang biasa digunakan adalah top left dan bottom right.
- straight bounding rectangle -> kotak lurus, gabisa menyesuaikan gambar yang ada rotasinya
- rotated rectangle -> ini bisa
- convex hull ->
cv2.convexHull()-> mencari convexity defects yang kemudian diminimalisir. Intinya bikin contours. - minimum enclosing circle -> lingkaran paling kecil
- fit ellipse
Color Space
- Faktor yang memengaruhi penglihatan -> cahaya, pantulan, tekstur (specularity), jarak, sudut, sensitifitas sensor
- Primary color = RGB. Secondary -> pada warna additive, G + B = cyan, R + G = yellow, R + B = magenta. pada warna subtractive, cyan + yellow = G, cyan + magenta = B, magenta + yellow = R.
- Merah gelombangnya paling panjang. Paling pendek biru
- Color models
- RGB -> aditif, display monitor
- CMY -> substractive, tinta, percetakan
- HSI dan HSL -> keperluan seni, psikologi, pengenalan
- HSV dan YCbCr -> deteksi kulit
- YUV dan YIQ -> untuk TV (kompresinya bagus)
- RGB -> setiap channelnya 8 bit (0-255)
- Intensitas $I = \dfrac{R+G+B}{3}$
- Normalisasi R (0-1), $r = \dfrac{R}{R+G+B}$
- Normalisasi G (0-1), $g = \dfrac{G}{R+G+B}$
- Normalisasi B (0-1), $b = \dfrac{B}{R+G+B}$ atau $b = 1 - (r + g)$
- CMY/CMYK -> tinta
- RGB (0-1) ke CMY -> $C = 1.0 - R$, $M = 1.0 - G$, $Y = 1.0 - B$
- CMY ke RGB (0-1) -> $R = 1.0 - C$, $G = 1.0 - M$, $B = 1.0 - Y$
- CMY ke CMYK -> $K = min(C, M , Y)$, terus tiap CMY nya di kurangi dengan $K$
- HSI (hue, saturation, intensity) -> hanya butuh mengatur hue. Untuk mengidentifikasi warna dari obyek yang berbeda. Rumus liat PPT.
- HSV -> rumus liat PPT
- HSL -> lightness
- YCbCr -> Y luminance/intensitas/cahaya, CbCr -> chrominance/warna. Cb biru dan Cr merah. Biasanya digunakan untuk fotografi digital.
- YIQ -> Y lebih banyak bit nya, karena manusia lebih sensitif thdp cahaya. Ruang warna NTSC.
- YUV -> Untuk video digital dan kompresi JPEG dan MPEG.
Morfologi Citra
https://penny-xu.github.io/blog/mathematical-morphology
- Dilasi -> memperbesar, memperluas, melebar. Kalo ada yang pixel yang nyentuh SE, tengah2nya bakal nambahin warna tsb. $A \oplus B = {z | z = a + b, \text{dengan } a \in A \text{ dan } b \in B}$ . Liat perhitungan di PPT, liat animasi di link
cv2.dilate()
- Erosi -> pengikisan. Kalo cocok semua antara SE dan pixel, berarti bakal gak diilangin. Selain itu diilangin.
cv2.erode()
- Structuring element (SE) -> mask untuk operasi morfologi
- Dilasi dan erosi bersifat duals, $(A \ominus B)^{C}=A^{C}\oplus \widehat{B}$. Dimana $\widehat{B}$ adalah bentuk refleksi dari $B$.
- Opening -> menghaluskan contour objek, mematahkan jembatan kecil, menghilangkan tonjolan tipis
- $A \circ B = (A \ominus B) \oplus B$ -> di erosi dulu baru di dilatasi
cv2.MORPH_OPEN
- Closing -> kebalikan opening
- $A \bullet B = (A \oplus B) \ominus B$ -> di dilatasi dulu baru di erosi
cv2.MORPH_CLOSE
- Hit Or Miss / skeleton image -> $A \circledast B = (A \ominus B_{1}) \cap (A^{C}\ominus B_{2})$ dimana $B$ adalah strel/konstruktor/SE (?)
- Boundary Extraction -> $\beta (A) = A - (A \ominus B)$. Intuisinya gambar ori dikurangi sama gambar yang versi terkikis.
- Thickening -> pokonya pinggirannya ditambah piksel, nggak perlu SE
Intensity Transformation
- Transformasi pada tingkat keabuan dasar / Basic gray level transformation
- Transformasi Linear -> citra negatif
- Transformasi Logaritmik -> $G = c \log (F+1)$ dimana $F$ adalah gambar. Kalo inverse log $G = c \log (L-F+1)$ dimana $c$ adalah konstanta yang berefek ke perubahan kontras. Memetakan grey level ke output yang range nya lebih luas. Memperluas nilai piksel yang gelap dan memampatkan nilai pixel terang. atau kebalikannya.
- Transformasi Power-Law -> $s = cr^{\gamma}$ dimana $c$ dan $\gamma$ adalah konstanta positif. makin tinggi gammanya makin gelap, soalnya kan $r$ atau gambarnya itu dalam bentuk ternormalisasi (0-1), terus kalau dipangkatin akan makin kecil –> makin gelap.
- Fungsi transformasi linear sepotong-sepotong
- Contrast stretching dan thresholding
- contrast stretching untuk menajamkan gambar dengan cara meningkatkan rentang dinamis tingkat keabuan. -> pixel terang makin terang dan pixel gelap makin gelap.
- thresholding sama kek yang awal2
- Gray level slicing
- Bit plane
- Contrast stretching dan thresholding
Domain Spatial
- Filter = windows = mask pada konvolusi
- Jenis-jenis filter
- Smoothing spatial filter -> low pass filter. reduce noise, blur edge
- Mean filter -> jadi ngeblur. $W = \dfrac{1}{9} \cdot \begin{bmatrix} 1 & 1 & 1 \ 1 & 1 & 1 \ 1 & 1 & 1 \end{bmatrix}$
- Median filter -> hilangin noise pake median
- Gaussian filter -> ngeblur tapi ada tingkatannya. Semakin besar $\sigma$ maka semakin ngeblur
- Sharpening spatial filter -> menghilangkan buram, menonjolkan tepi. Dasarnya adalah spatial differentiation. Turunan kedua untuk perbaikan citra / image enhancement karena bisa meningkatkan kedetilan (sharpening).
- Laplacian filter -> $\nabla^2 f = \dfrac{\partial^2 f}{\partial x^2} + \dfrac{\partial^2 f}{\partial y^2}$ dimana $\dfrac{\partial^2 f}{\partial x^2} = f(x+1,y) + f(x-1,y) - 2f(x,y)$ dan $\dfrac{\partial^2 f}{\partial y^2} = f(x,y+1) + f(x,y-1) - 2f(x,y)$
- Bentuk kernel laplacian adalah $\begin{bmatrix} 0 & 1 & 0 \ 1 & -4 & 1 \ 0 & 1 & 0 \end{bmatrix}$ Tapi ini hasilnya cuma edgenya aja. Jadi perlu $g(x, y) = f(x, y) - \nabla^{2}f$ dimana $f$ adalah citra aslinya. Untuk skip step pengurangan itu bisa pake variasi kernel $\begin{bmatrix} 0 & -1 & 0 \ -1 & 5 & -1 \ 0 & -1 & 0 \end{bmatrix}$, nanti kalo di konvolusi hasilnya langsung sharp. Masih banyak lagi variasi kernel laplacian.
- Laplacian filter -> $\nabla^2 f = \dfrac{\partial^2 f}{\partial x^2} + \dfrac{\partial^2 f}{\partial y^2}$ dimana $\dfrac{\partial^2 f}{\partial x^2} = f(x+1,y) + f(x-1,y) - 2f(x,y)$ dan $\dfrac{\partial^2 f}{\partial y^2} = f(x,y+1) + f(x,y-1) - 2f(x,y)$
- Smoothing spatial filter -> low pass filter. reduce noise, blur edge
- Edge Detection -> memanfaatkan gradien. Vektor menyatakan arah perubahan sementara magnitude menyatakan besaran perubahan.
- vektor -> $G[f(x, y)] = \begin{bmatrix} G_x \ G_y \end{bmatrix} = \begin{bmatrix} \frac{\partial f}{\partial x} \ \frac{\partial f}{\partial y}\end{bmatrix}$
- magnitude -> $G[f(x, y)] = \sqrt{G^{2}{x}+G^{2}{y}}$
- Operasi gradien pada $\begin{bmatrix} z1 & z2 & z3 \ z4 & z5 & z6 \ z7 & z8 & z9 \end{bmatrix}$
- Roberts -> $g_{x}= (z9 - z5)$ dan $g_{y} = (z8 - z6)$
- Prewitt -> $g_{x}= (z7 + z8 + z9) - (z1 + z2 + z3)$ dan $g_{y} = (z3 + z6 + z9) - (z1 + z4 + z7)$
- Sobel -> $g_{x}= (z7 + 2z8 + z9) - (z1 + 2z2 + z3)$ dan $g_{y} = (z3 + 2z6 + z9) - (z1 + 2z4 + z7)$
- Non-Maxima Supression (NMS) -> menghilangkan tepi yang lemah dan filling gaps.
HoG
- Metode ekstraksi ciri untuk mendeteksi objek pada gambar. bentuk lokal dari objek bisa dikenali dari distribusi intensitas gradien atau orientasi tepi
- Fitur deskriptor -> representasi gambar dalam bentuk vektor yang udah diekstraksi yang penting-penting aja.
- Tahap-tahap HoG
- Preprocessing -> aspect ratio harus 1:2, biasanya 64 x 128
- Hitung gradien pada gambar -> pake sobel, hitung magnitude sama orientasi gradien (angle). Intinya kan dari sobel itu dapat $g_x$ dan $g_y$ nah itu diconvert ke koordinat polar yang outputnya mag dan angle. $g_x$ efeknya di garis vertikal, $g_{y}$ di garis horizontal, magnitude di intensitasnya.
- Hitung distribusi gradien pada cell 8x8 -> untuk tiap patch nya dicari gradient mag dan direction. histogramnya 9 bins dengan range(0, 161, 20). Ada aturannya, liat PPT.
- 16x16 normalization
- Menghitung HOG feature vector -> arah dominan dari histogramnya membentuk objeknya.
Matching
- Mencocokkan template gambar dengan gambar utuh. Template digunakan untuk identifikasi objek mirip di gambar full nya.
- Bit level matching -> yes/no approach soalnya cuma 0/1
- Grey level matching -> gak bisa yes/no, perlu pengukuran jarak/error/similarity. Bisa pake MSE, euclidean distance, correlation, dll
- Cara matching nya itu di slide-slide gitu template nya
- Cara lain untuk ngukur bisa pake structural similarity index (SSIM) dengan color space HSV -> luminance comparison, contrast comparison, structure comparison
- Bentuk lainnya itu MSSIM yang berarti di rata-rata dengan cara dibagi dengan sejumlah $M$ blok
- di PPT ada facial detection
- skin segmentation -> RGB jadi YCbCr dan HSV. Yang dipake thresholding itu Cb, Cr, sama hue
- Kualitas segmentasi kulit sangat berpengaruh
Pengenalan Wajah
- Algoritma eigenface -> pada setiap wajah di database dihitung dan menghasilkan eigenvalue dan eigenvector yang mana digunakan untuk mencari nilai bobot. Nanti kek diselisihin sama nilai eigenface dengan wajah yang dicari, yang paling kecil berarti paling cocok.
- Cara untuk mendapatkan eigenface intinya adalah mengalikan matriks gabungan $S$ dengan eigenvector yang memiliki eigenvalue terbesar, kemudian di normalisasi
GLCM
- Ekstraksi fitur tekstur. Capture pattern e.g. repetitiveness and granularity
- Macam-macam texture features:
- Statistical
- General stats params (mean, median, dll)
- Autocorrelation features
- Laws textures energy features
- Co occurange matrix based features (GLCM)
- LBP features
- Structural
- Model
- Fractal features
- Random field features
- Filter
- Gabor filters
- Wavelet
- Statistical
- Langkah-langkah GLCM
- Karena GLCM itu gray level, maka harus diconvert jadi grayscale dulu pake $\text{gray} = 0.299 \times R + 0.587 \times G + 0.114 \times B$
- Membuat co occurance matrix. Ada 2 parameter, distance dan orientation. distance itu seberapa jauh pixel pair yang harus dicek. Kalo orientation ke arah mana pair pixelnya
- matriks GLCM harus simetris, jadi $C = C + C^{T}$ dimana $C$ adalah matriks GLCM
- Habis itu dinormalisasi dengan dibagi dengan total nilai matriks GLCM
- Selesai, dari sini bisa hitung fitur GLCM
- Fitur GLCM:
- Kontras
- Dissimilarity
- Homogenity
- Angular Second Moment
- Energy
- Correlation
- Co occurance matrices capture properties of texture but not directly useful for further analysis. Makanya perlu second order stats pake fitur2 di atas.
- Bisa juga pake haralick features. Caranya pake konvolusi buat hitung GLCM. Terus ada banyak juga fitur2 nya.
ResNet
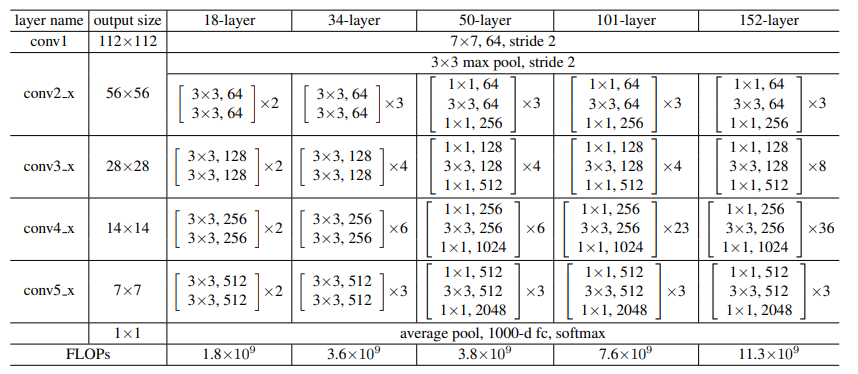
- Idenya bikin cnn yang dalem banget, tapi somehow bisa solve vanishing gradient
- Caranya pake residual connection/skip connection.
- Pada setiap stage nya ada residual connectionnya
- Perbedaan antar variasi ResNet cuma di kedalamannya.
EfficientNet
- Mempelajari lebih dalam tentang scaling law dalam CNN. Ada 3 variabel yang diperhatikan: width, depth, dan resolution. Inti dari paper ini membuat compound yang mana bisa menyeimbangkan ketiga variabel tsb.
- Constraint dari ketiga variabel tersebut harus $\alpha \times \beta^{2} \times \gamma ^{2}= 2$, terus di grid search.
- Step trainingnya:
- grid search untuk cari $\alpha, \beta,\gamma$ terbaik
- Kalo udah ketemu, di pangkatin $\alpha^\phi, \beta^\phi,\gamma^\phi$
- Jadi perbedaan utama dari B0, B1, B2, dll itu ada di koefisien $\phi$ nya
YOLO

- object detection
- Ada backbone, neck, sama head. Backbone itu untuk feature extraction. Head itu udah hampir detect. Untuk setiap blok detect itu deteksi bbox sama class nya.
- Di arsitekturnya ada 3 blok detect, masing-masing disesuaikan sama ukurannya.
- Untuk penjelasan blok2 nya liat poster di atas aja
MobileNet
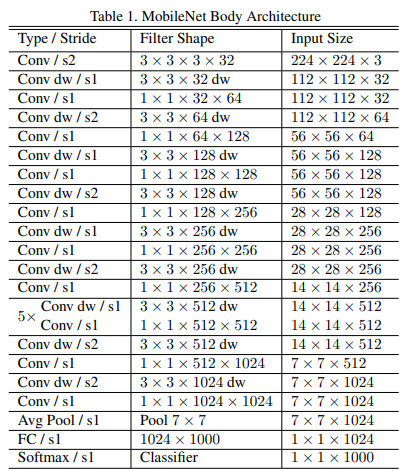
- Object detection
- Kuncinya di depthwise separable convolution
- depthwise convolution -> dihitung per channel-nya. Hasilnya masih 3 channel terpisah
- pointwise convolution (1x1 conv) -> nah disini digabungin makanya dia $1 \times 1 \times \ M$ dimana $M$ adalah jumlah channel
- Conv block normal biasanya 3x3 conv-BN-ReLU. Sementara depthwise separable conv itu 3x3 dw conv-BN-ReLU-1x1 conv-BN-ReLU
Inception
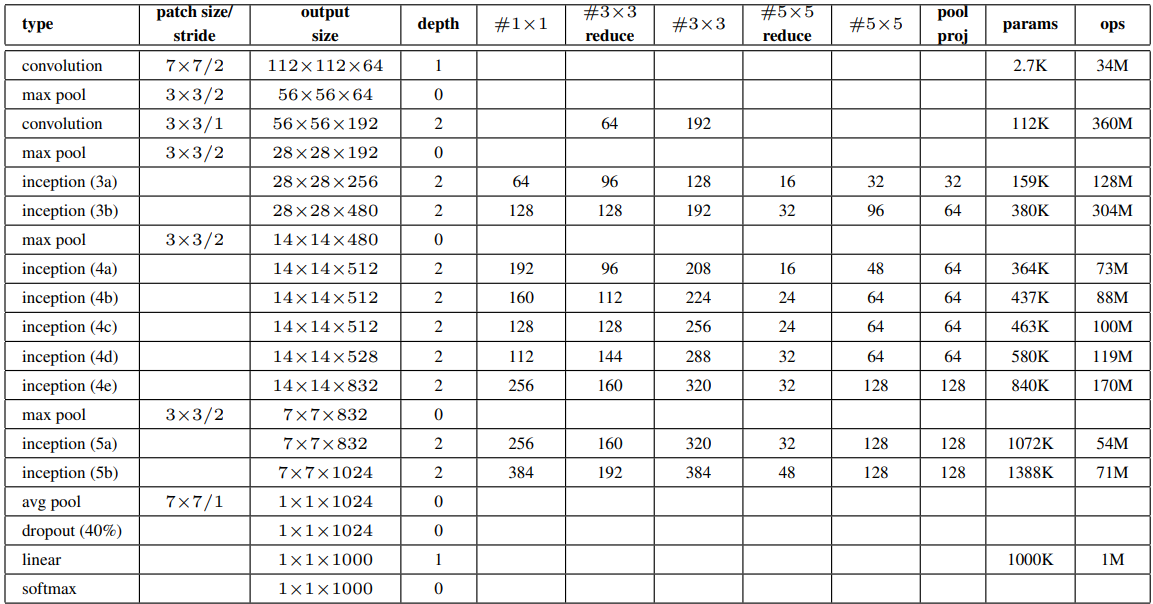
- Intinya propose inception module yang isinya macam-macam conv dengan kernel size yang beda, sama ada max pool juga, terus hasilnya di concat
- Googlenet pake ini
- Misal ada conv 1x1, terus ada 3x3, terus ada 5x5. Nah perhitungan ini bisa berat, makanya ada dimentionality reduction pake conv 1x1 sebelum masuk ke 3x3 sama 5x5
- Kalo max pooling 3x3 itu nantinya masuk ke conv 1x1 sebelum diconcat.
- Layer 1x1 buat ngelakuin DR ini disebut dengan bottleneck layer.
$$\text{output size} = \dfrac{\text{input size} - \text{kernel size} + 2 \times \text{padding}}{\text{stride}} + 1$$